godaddy域名购买孍孎孏老域名购买交易出售,已备案域名权重高pr收录外链反链老域名
分类目录归档:六六互联
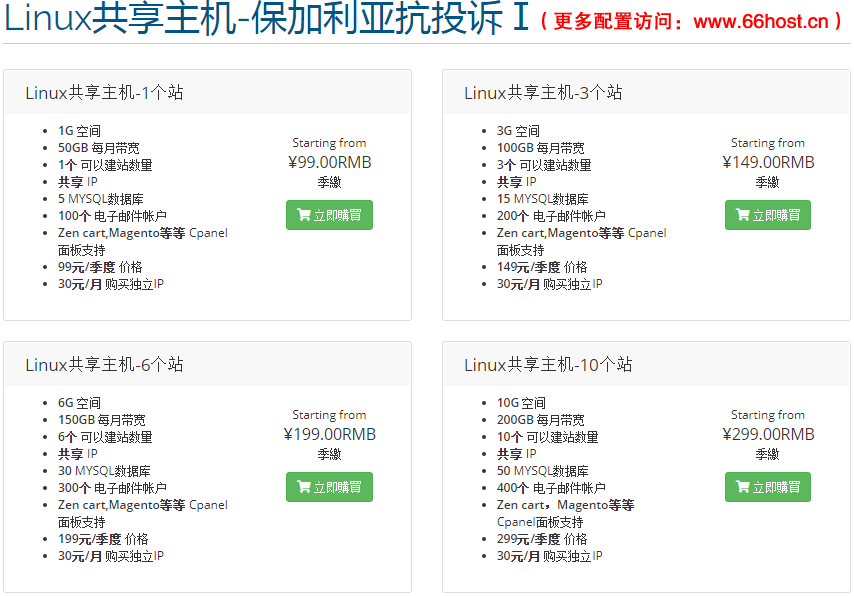
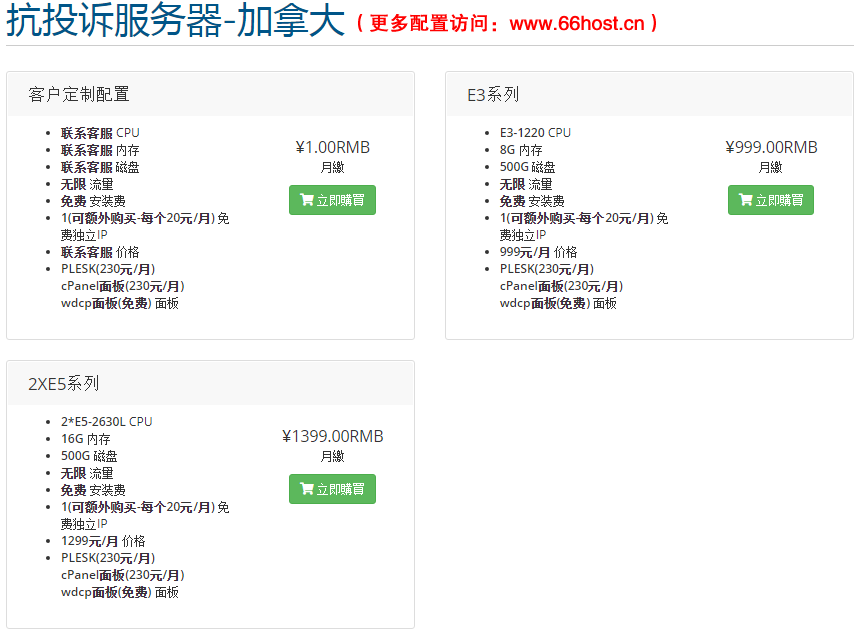
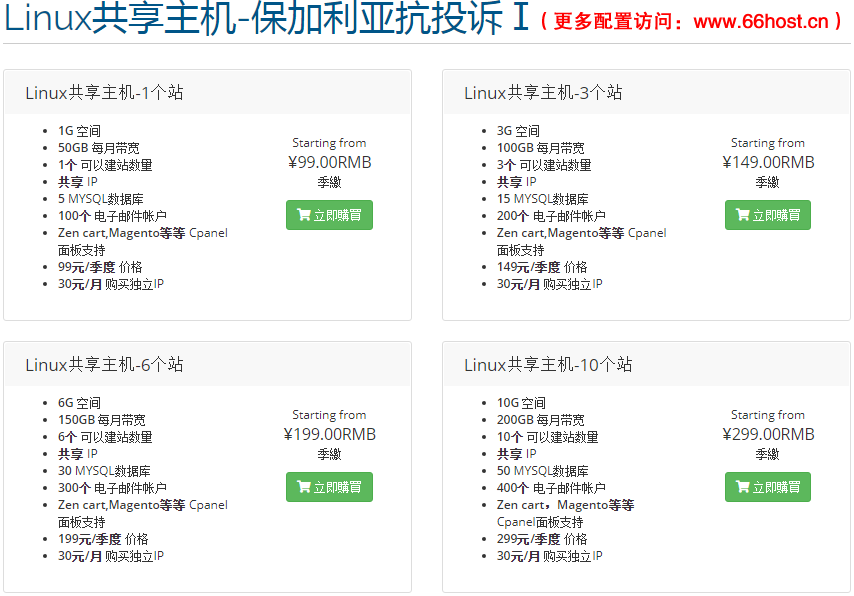
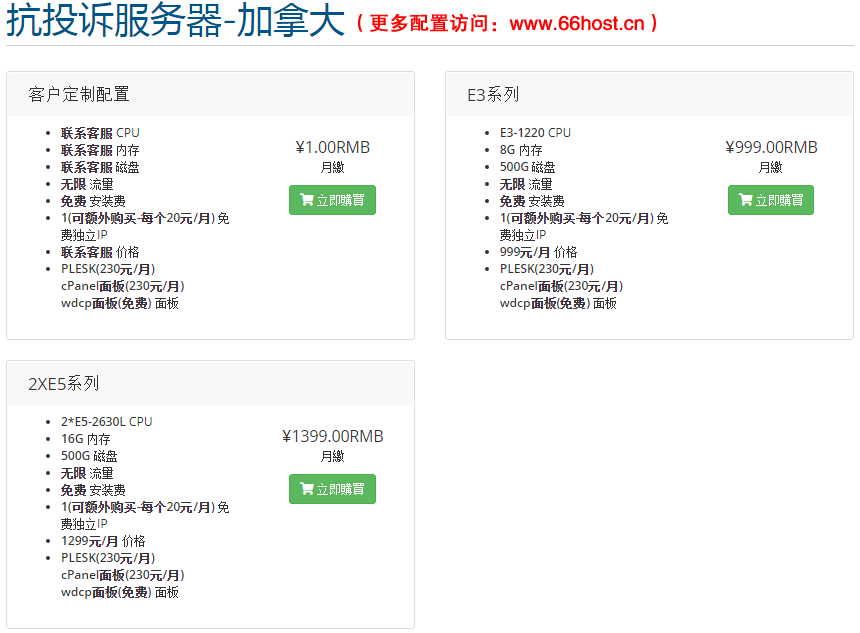
外贸抗投诉机房娈孋孊主机免投诉vps,仿牌服务器美国仿牌空间租用,防投诉主机
外贸抗投诉机房娈孋孊主机免投诉vps,仿牌服务器美国仿牌空间租用,防投诉主机



外贸服务器严禁诈骗等国内违法用途,国内在严打诈骗。



怎么在服务器上配置网页GZIP压缩
怎么在服务器上配置网页GZIP压缩
IIS6集成了Gzip,需要手动操作,下面写下大概步骤:
1、在服务器中新建一个文件夹,名称任意,给本机用户添加写入权限。
2、进入IIS管理器,IIS管理器>网站 右键进入“属性”面板,切换到“服务”选项卡,勾选HTTP压缩中两项,如果仅仅想压缩静态文件,那么第一项就算了。临时目录就是刚才新建的那个文件夹。
3、确认后进入IIS管理器>Web服务扩展,点击“添加一个新的Web服务扩展”,在弹出的面板中首先输入扩展名,名称任意;然后在“要求的文件”中添加文件,其实就是输入gzip.dll所在的路径。如果不是特立独行的服务器,那么这个位置基本上就是“C:WINDOWSsystem32inetsrvgzip.dll”,确认后记得将“设置扩展状态为允许”勾选。
4、进入C:WINDOWSsystem32inetsrv这个目录下,找到一个叫MetaBase.xml的文件,直接修改保存是不行的,因为IIS服务正在使用该文件。强烈建议先备份该文件,再在一个副本上修改。用文本编辑器打开副本,用查找功能找到“IIsCompressionScheme”,共有3处,都在一起,分别是deflate、gzip和Parameters,deflate也是一种压缩格式,不过性能上不如gzip。需要修改的是deflate和gzip这两段,参数基本一样,都要修改。
HcDynamicCompressionLevel是用来设置压缩率,默认是0,最高是10。低压缩级别生成稍大一些的压缩文件,但对 CPU 和内存资源的总体影响较小。高压缩级别通常会生成较小的压缩文件,但会占用较多的 CPU 时间和内存。有人说设置成9性价比最高。
HcFileExtensions是用来设置压缩的静态文件扩展名,默认是htm、html、txt,根据网站的自身情况添加扩展名,最基本的是js、css。添加时注意原有的换行格式。
HcScriptFileExtensions是用来设置压缩的动态文件扩展名,默认是asp、dll和exe,根据需要自行添加扩展名,无外乎aspx、php等。可以将这一项的默认删除留空,这样所有的动态响应都以压缩方式发送。另外,还将动态压缩 HcFileExtensions 中所有未指定的静态文件类型,并且因此不将它们放入缓存。同样地,必须将 HcDoDynamicCompression 设置为 true,以进行动态压缩。
Linux中init进程介绍及常用方法
init(为英语:initialization的简写)是Unix和类Unix系统中用来产生其它所有进程的程序。它以守护进程的方式存在,其进程号为1。
所谓的init进程,它是一个由内核启动的用户级进程。
内核自行启动(已经被载入内存,开始运行,并已初始化所有的设备驱动程序和数据结构等)之后,就通过启动一个用户级程序init的方式,完成引导进程。所以init始终是第一个进程(其进程编号始终为1)。
内核会在过去曾使用过init的几个地方查找它,它的正确位置(对Linux系统来说)是/sbin/init。如果内核找不到init,它就会试着运行/bin/sh,如果运行失败,系统的启动也会失败。
BSD风格
BSD init运行存放于’/etc/rc’的初始化shell脚本,然后启动基于文本模式的终端(getty)或者基于图形界面的终端(窗口系统,如X)。 这里没有运行模式的问题,因为文件’rc’决定了init如何执行。
优点: 简单且易于手动编辑。
缺点: 如果第三方软件需要在启动过程执行它自身的初始化脚本,它必须修改已经存在的启动脚本,一旦这种过程中有一个小错误,都将导致系统无法正常启动。
值得注意的是,现代的BSD派生系统一直支持使用’rc.local’文件的方式,它将在正常启动过程接近最后的时间以子脚本的方式来执行。这样做减少了整个系统无法启动的风险。然后,第三方软件包可以将它们独立的start/stop脚本安装到一个本地的’rc.d’目录中(通常这是由 ports collection/pkgsrc 完成的)。都被分成更小的子脚本,和SysV类似。rcorder通常根据在rc.d目录中脚本之间的依赖关系来决定脚本的执行顺序。
SysV风格
System V init检查’/etc/inittab’文件中是否含有’initdefault’项。 这告诉init系统是否有一个默认运行模式。如果没有默认的运行模式,那么用户将进入系统控制台,手动决定进入何种运行模式。
优点: 灵活性强
缺陷: 比较复杂
其他风格
很多人一直努力地从某些方面改进传统的init守护进程,使它变得更完善。下面列出的是一些改进,没有特别的顺序:
SystemStarter, 用来替代launchd—Apple Mac OS X开启进程
Initng, 完全代替init,可以异步开启进程
Upstart, 完全代替init,可以异步开启进程由Ubuntu使用
Service Management Facility, 完全代替/重新设计Solaris启动Solaris 10
runit, 跨平台的完全代替init可以并行启动服务
BootScripts, GoboLinux
Mudur, 用Python写成的init替代品, 可以异步开启进程,Pardus Linux发行版
systemd, 完全替代init,可并行启动服务,并能减少在shell上的系统开销,为Fedora、ArchLinux所使用
System V中运行模式
Linux用init命令可以实现关机、重启、切换模式:
System V中运行模式描述了系统各种可能的状态。通常会有8种运行模式,即运行模式0到6和S或者s。其中运行模式3为”保留的”运行模式:
/etc/inittab
1#
2# inittab This file describes how the INIT process should set up
3# the system in a certain run-level.
4#
5# Author: Miquel van Smoorenburg,
6# Modified for RHS Linux by Marc Ewing and Donnie Barnes
7#
8# Default runlevel. The runlevels used by RHS are:
9# 0 – halt (Do NOT set initdefault to this)
10# 1 – Single user mode
11# 2 – Multiuser, without NFS (The same as 3, if you do not have networking)
12# 3 – Full multiuser mode
13# 4 – unused
14# 5 – X11
15# 6 – reboot (Do NOT set initdefault to this)
16#
17id:3:initdefault:
0是关机
1是单用户
2是多用户,不联网
3是多用户
4是不使用的
5是xwindows,也就是有界面的
6是重启
init命令很简单。直接输入init + 你想要的模式回车就行。
比如输入 : init 0就是关机
init 3 就是切换到多用户
init 5 就是切换到界面
init 6 就是重启
内存数据库的基本原理与应用
内存数据库是以牺牲内存资源为代价换取数据处理实时性的,内存数据库和磁盘数据库都是当今信息社会里每个企业所必须的关系型数据库产品,磁盘数据库解决的是大容量存储和数据分析问题,而内存数据库解决的是实时处理和高并发问题。两者的存在是相辅相成的,内存数据库的事务实时处理性能要远强于磁盘数据库。但是相对的,他的数据安全方面还没有达到磁盘数据库比肩的地步。
内存数据库将物理内存作为数据的第一存储介质,而将磁盘作为备份。随着电信业务的发展,系统对实时性的要求和对业务灵活修改的要求非常高,在此种情况下对于内存数据库的需求也越来越高。磁盘数据库的做法是将数据存入内存中进行处理,这种方式的可管理性及数据安全可靠性都没有保障。而内存数据库正是针对这一弱点进行了改进。
实际上,内存数据库并不是一项时髦技术,其出现于上世纪60年代末,但由于市场的需求原因在90年代后期才开始发展。作为新一代数据库,Altibase产品已经走向混合型数据库,其版本Altibase 4.0已经有一套自带的磁盘数据库,用户一旦购买了Altibase的内存数据库,就无须再购买磁盘数据库。它把热数据(经常被使用的、访问比较高的、经常要运算的数据)放在内存数据库里,而把历史性数据放在磁盘数据库里,可为用户进一步减少投资。
对于内存数据库而言,可以将同样数据库的部分内容存放于磁盘上,而另一部分存放于内存中。用户可以选择将数据存储在内存表中以提供即时的数据访问。若访问时间不紧急或数据存于内存中所占空间过大时,用户可将这些数据存入磁盘表中。
比如,在手机用户开始拔打电话时,如果应用基于内存数据库技术的混合数据管理引擎,就通过内存表检索其服务选项并立即验证用户身份,而将通话清单和计费清单归档到磁盘表中。从而,达到了速度与资源使用的平衡。
内存数据库的技术,一个很重要的特点,是可以对内存中的数据实现全事务处理,这是仅仅把数据以数组等形式放在内存中完全不同的。并且,内存数据库是与应用无关的,显然这种体系结构具有其合理性。内存引擎可以实现查询与存档功能使用的是完全相同的数据库,同时内存表与磁盘表也使用的是完全相同的存取方法。存储的选择,对于应用开发者而言是完全透明的。
对于内存数据库而言,实现了数据在内存中的管理,而不仅仅是作为数据库的缓存。不像其它将磁盘数据块缓存到主存中的数据库,内存数据库的内存引擎使用了为随机访问内存而特别设计的数据结构和算法,这种设计使其避免了因使用排序命令而经常破坏缓存数据库性能的问题。通过内存数据库,减少了磁盘I/O,能够达到了以磁盘I/O 为主的传统数据库无法与其相比拟的处理速度。
因此,内存数据库技术的应用,可以大大提高数据库的速度,这对于需要高速反应的数据库应用,如电信、金融等提供了有力支撑。
(以上引自 http://hi.baidu.com/bluesky0205/blog/item/2dde5d08df57fe9f0b7b8258.html)
由于把大多数数据都放在内存中进行操作,使得内存数据库有着比磁盘数据库高得多的性能表现,这一特点非常契合电信企业运营支撑系统对实时性的要求。
电信业的竞争正在全方位地展开,这种竞争必然带来新的价值链模式以及新的计费方式,这些变化对目前的电信运营支撑系统是一个挑战。比如,多种业务的计费环节将不再是单一的按照时长或通信距离收取费用,而可能是根据时长、内容、使用量等多种参数的组合计费。为了应对这些挑战,电信企业先后引入了内存数据库,以提高后台数据管理的实时性、精确性和灵活性。
尽管内存数据库已不是传统磁盘数据库的概念,但是内存数据库本质上还是数据库,它也具有一般数据库的基本功能:
■ 永久数据的管理,包括数据库的定义、存储、维护等;
■ 完成各种数据操作,如查询处理、存取、完整性检查;
■ 事务管理,包括调度与并发控制等;
■ 对存取的控制和安全性检验;
■ 具有数据库的可靠性恢复机制。
相对于利用程序开发手段调用内存处理来说,内存数据库自有其优势。首先,内存数据库是产品化的数据库管理软件,极大缩短了开发周期; 其次,内存数据库有着开放的平台和接口,程序开发和移植更加灵活便捷,也便于维护和二次开发; 第三,可以通过使用统一的SQL语言方便地查询内存中的数据; 最后,能在数据库中保障数据的安全性和完整性。这些优势,对于快速部署和简化维护都是有利的。
但内存数据库也有其不可避免的缺点,比如: 不容易恢复,内存数据库中的数据不总是永久的,为了保证实时,也不一定是一致和绝对正确的,有的是短暂的,有的是暂时不一致或非绝对正确的。
电信企业一直是内存数据库的主要用户,近几年来,随着计算机硬件技术的飞速发展、内存容量的提高、价格下跌以及计算机进入64位时代操作系统后可以支持更大的地址,为内存数据库的实现提供了可能。目前内存数据库在电信行业的应用也日趋成熟,已有超过90G的电信系统案例,能自动扩展内存空间,不需要重启数据库,提供ESOL自定义存储过程,支持多线程,开发效率高,程序移植容易等等。
下面以两个例子来介绍内存数据库的应用。
电信计费数据的加载
电信的二次批价和实时累账是计费系统中的两个必备功能。
所谓二次批价是相对于一次批价来说的。
一次批价是按照国家标准资费来进行价格计算,比如: 全球通每分钟本地通话为0.4元,在一次批价完成后,会根据这个用户的套餐进行再一次的计算。以北京全球通用户接听4分钟的电话为例,一次批价完成后,这条话单的价格是1.6元,如果这个用户参加了10元包月接听套餐,那么在二次批价后,这次通话的费用就为0元。
一次批价是用于各大运营商之间结算的,而二次批价是针对用户个人的。
实时累账是将用户从每月1号到目前为止的所有费用累加起来,也就是用户目前可以通过10086查到截止到前一天的实时话费。累账值可以帮助用户控制高额话费或是供用户即时查询消费信息。
二次批价和实时累账过程涉及用户资料、用户套餐等与用户相关的信息,电信支撑系统在开始批价时必须加载这些数据。稍大一点的省级运营商的这些数据就会超过1000万条,计费处理模型也由于套餐的组合、产品的组合以及不同的优惠规则变得相当复杂,加载这部分数据对系统而言是一笔不小的开销,这就使得现在的计费处理速度比较慢,而且很难做到对数据的实时更新。内存数据库的引入在一定程度上解决了这个问题。
在计费二次批价过程中数据量最大的是详单数据,这部分数据不用放在内存数据库中,每处理完一个话单文件或达到设定的提交记录数时直接操作磁盘数据库,不会影响系统性能。最急切的是将用户资料、套餐、营业套餐和计费套餐对应关系数据、计费套餐模型数据及用户累计数据放到内存数据库中,这部分数据查询操作远比数据新增和更新操作要频繁。除了这些数据外,当然还有应用需要的其他数据也都可以加载到内存数据库。
在采用内存数据库后,用户通过营业部或客户查询实时话费的时候完全可以做到实时,比目前只能提供查询到前一天的实时话费在业务上有了质的飞跃。因为系统在处理这部分数据时查询流程和以前的完全一样,但系统省去了以往内存中的数据和磁盘数据库数据同步的环节,所以就能做到了实时查询。对于信控来说也同样,以往系统在累完账后要按照一定周期刷新信控数据,这就存在一个时间差,不能够完全做到实时。
而采用内存数据库后,信控可以直接取得内存数据库中的实时话费累计表中的数据,完全实现实时预警、停机。二次批价和累账中采用内存数据库后,对防欺诈、收入保障系统也有相当大的好处,这样能够充分保证运营商的切身利益。
另外,在采用内存数据库后,整体提高了系统批价、累账的处理速度,大大缓解访问磁盘数据库的压力,提高数据查询、修改、删除的效率,也为后付费和预付费的融合提供了可能。
电信计费数据的同步
电信营业数据和计费系统中的数据总是在不断的变化中,这就涉及内存数据库中的数据和磁盘数据库数据的同步问题(为了描述清楚,这里的磁盘数据库以Oracle DB为例来说明)。数据同步包括两部分: 从内存数据库到Oracle DB数据同步和从Oracle DB到内存数据库的同步。
1. Oracle DB到内存数据库同步
这部分数据同步采用增量表的方式,营业系统或CRM新增或更新的数据将生成到Oracle的增量表中,计费后台程序先到这些增量表中查询数据。如果能在这些增量表中查到数据就把这些数据更新到内存数据库对应表中,如果查不到,就直接从内存数据库中直接查询,从而保证了数据的完整性和实时性。由于增量表的数据量一般会很小,所以这部分操作不会影响系统的性能。
2. 内存数据库到Oracle DB同步
由于Oracle的计费后台批价、累账数据几乎都加载到了内存数据库中,所以Oracle数据库对应的数据表将主要用于对内存数据库的数据备份。
用户最新的实时话费等信息都保存在内存数据库中,实时话费查询将直接连接到内存数据库中查询,保证用户得到最新的费用信息。信控也直接从内存数据库查询数据,因此对Oracle中的这部分数据已经没有实时性的要求。这时内存数据库到Oracle的同步可以由应用程序生成文件,定时地往Oracle数据库中同步备份,或者采用Oracle 存储过程在系统相对空闲时间段进行数据导入就可以了。
总体而言,由于市场与技术的快速发展,电信业务在不断扩充,其运营和管理不断优化,传统的一些支撑系统的架构已经逐渐不能满足日益增长的业务要求和客户需求,引入一些新的技术来解决我们生产中遇到的问题是必然的。比如采用内存数据库来代替以前的共享内存技术,使得原来在内存中不标准的东西,包括接口、格式和管理都标准化了。
内存数据库只是多种新技术中有代表性的一种而已,只要解放思想、选用得当,完全可以在投入不大的情况下克服系统中的瓶颈,以最小的代价获得最大回报。
Linux下常用文本处理命令
Linux下面有很多经典的非常有用的命令,其中处理文本的命令就有很多。这些小工具经过了几十年时间的洗礼,现在已经变成了经典,已经变成了Linux下面的标准,其实它们一直是遵循着Linux的标准。下面就让我们一起看看这些经典的Linux文本处理命令。
一. sort
文件排序,通常用在管道中当过滤器来使用。这个命令可以依据指定的关键字或指定的字符位置,对文件行进行排序。使用-m选项,它将会合并预排序的输入文件。想了解这个命令的全部参数请参考这个命令的info页。
二. tsort
拓扑排序,读取以空格分隔的有序对,并且依靠输入模式进行排序。
三. uniq
这个过滤器将会删除一个已排序文件中的重复行。这个命令经常出现在sort命令的管道后边。
四. expand, unexpand
expand命令将会把每个tab转化为一个空格。这个命令经常用在管道中。
unexpand命令将会把每个空格转化为一个tab。效果与expand命令相反。
五. cut
一个从文件中提取特定域的工具。这个命令与awk中使用的print $N命令很相似,但是更受限。在脚本中使用cut命令会比使用awk命令来得容易一些。最重要的选项就是-d(字段定界符)和-f(域分隔符)选项。
六. paste
将多个文件, 以每个文件一列的形式合并到一个文件中,合并后文件中的每一列就是原来的一个文件。与cut结合使用,经常用于创建系统log文件。
七. join
这个命令与paste命令属于同类命令。但是它能够完成某些特殊的目地。这个强力工具能够以一种特殊的形式来合并两个文件,这种特殊的形式本质上就是一个关联数据库的简单版本。
join命令只能够操作两个文件。它可以将那些具有特定标记域(通常是一个数字标签)的行合并起来,并且将结果输出到stdout。被加入的文件应该事先根据标记域进行排序以便于能够正确的匹配。
八. head
把文件的头部内容打印到stdout上(默认为10行,可以自己修改)。这个命令有一些比较有趣的选项。
九. tail
将一个文件结尾部分的内容输出到stdout中(默认为10行)。通常用来跟踪一个系统logfile的修改情况,如果使用-f选项的话,这个命令将会继续显示添加到文件中的行。
十. wc
wc可以统计文件或I/O流中的”单词数量”。
十一. fold
将输入按照指定宽度进行折行。这里有一个非常有用的选项-s,这个选项可以使用空格进行断行(译者:事实上只有外文才需要使用空格断行,中文是不需要的)(请参考例子 12-23和例子 A-1)。
十二. fmt
一个简单的文件格式器。通常用在管道中,将一个比较长的文本行输出进行”折行”。
十三. col
这个命令用来滤除标准输入的反向换行符号。这个工具还可以将空白用等价的tab来替换。col工具最主要的应用还是从特定的文本处理工具中过滤输出,比如groff和tbl。(译注:主要用来将man页转化为文本。)
十四. column
列格式化工具。通过在合适的位置插入tab,这个过滤工具会将列类型的文本转化为”易于打印”的表格式进行输出。
十五. colrm
列删除过滤器。这个工具将会从文件中删除指定的列(列中的字符串)并且写到文件中,如果指定的列不存在,那么就回到stdout。colrm 2 4
探讨PHP普遍使用的缓存技术
在大部份情况下我们的网站都会使用数据库作为站点数据存储的容器。当你执行一个SQL查询时,典型的处理过程是:连接数据库->准备SQL查询->发送查询到数据库->取得数据库返回结果->关闭数据库连接。但数据库中有些数据是完全静态的或不太经常变动的,缓存系统会通过把SQL查询的结果缓存到一个更快的存储系统中存储,从而避免频繁操作数据库而很大程度上提高了程序执行时间,而且缓存查询结果也允许你后期处理。
以下是普遍使用的缓存技术
数据缓存:
这里所说的数据缓存是指数据库查询缓存,每次访问页面的时候,都会先检测相应的缓存数据是否存在,如果不存在,就连接数据库,得到数据,并把查询结果序列化后保存到文件中,以后同样的查询结果就直接从缓存文件中获得。
页面缓存:
每次访问页面的时候,都会先检测相应的缓存页面文件是否存在,如果不存在,就连接数据库,得到数据,显示页面并同时生成缓存页面文件,这样下次访问的时候页面文件就发挥作用了。(模板引擎和网上常见的一些缓存类通常有此功能)
内存缓存:
Memcached是高性能的,分布式的内存对象缓存系统,用于在动态应用中减少数据库负载,提升访问速度。
dbcached 是一款基于 Memcached 和 NMDB 的分布式 key-value 数据库内存缓存系统。
以上的缓存技术虽然能很好的解决频繁查询数据库的问题,但其缺点在在于数据无时效性,下面是项目中常用的方法:
时间触发缓存:
检查文件是否存在并且时间戳小于设置的过期时间,如果文件修改的时间戳比当前时间戳减去过期时间戳大,那么就用缓存,否则更新缓存。
设定时间内不去判断数据是否要更新,过了设定时间再更新缓存。以上只适合对时效性要求不高的情况下使用 ,否则请看下面。
内容触发缓存:
当插入数据或更新数据时,强制更新缓存。
在这里我们可以看到,当有大量数据频繁需要更新时,最后都要涉及磁盘读写操作。怎么解决呢?在日常项目中,通常并不缓存所有内容,而是缓存一部分不经常变的内容来解决。但在大负荷的情况下,最好要用共享内存做缓存系统。
到这里PHP缓存也许有点解决方案了,但其缺点是,因为每次请求仍然要经过PHP解析,在大负荷的情况下效率问题还是比效严重,在这种情况下,也许会用到静态缓存。
静态缓存:
这里所说的静态缓存是指HTML缓存,HTML缓存一般是无需判断数据是否要更新的,因为通常在使用HTML的场合一般是不经常变动内容的页面。数据更新的时候把HTML也强制更新一下就可以了。
其实一个缓存系统涉及的问题是比较多的,在这里只简单介绍一下平时的缓存思路,并没有介绍利用软件来实现缓存和写出具体代码。
带您走进VPS
VPS技术是利用最新虚拟化技术Xen在一台物理服务器上创建多个相互隔离的虚拟私有主机。每台美国VPS的运行和管理都与一台独立主机完全相同,都可分配独立公网IP地址、独立操作系统、独立超大空间、独立内存、独立CPU资源、独立执行程序和独立系统配置等。用户除了可以分配多个虚拟主机外,更具有独立服务器功能,可自行安装程序,单独重启服务器。
VPS是一项具备高弹性、高质量及低成本效益的服务器解决方案,是租用高端香港虚拟主机用户的最佳选择。
VPS虚拟服务器技术可以通过多种不同的方式灵活的分配服务器资源,每个虚拟化服务器的资源都可以有很大的不同,可以灵活的满足各种高端用户的需求。
VPS主机是一项服务器虚拟化和自动化技术,它采用的是操作系统虚拟化技术。操作系统虚拟化的概念是基于共用操作系统内核,这样虚拟服务器就无需额外的虚拟化内核的过程,因而虚拟过程资源损耗就更低,从而可以在一台物理服务器上可以实现更多的虚拟化服务器。这些VPS主机以最大化的效率共享硬件、软件许可证以及管理资源。每一个VPS主机均可独立进行重启,并拥有自己的root访问权限、用户、IP地址、内存、过程、文件、应用程序、系统函数库以及配置文件。
服务器和VPS的主要区别:
第一、硬件配置拥有权利不同:服务器是独立存在的物理硬件,拥有独立的CPU、内存、硬盘等配置资源,主要为网站以及一些软件应用提供运行平台;而VPS是利用软件在服务器中虚拟出来的,和别人共享服务器的硬件资源;
第二、 价格不同:独立服务器的价格要比VPS的价格贵的多,一般美国服务器最便宜的也需要500左右基本配置,高至上万元;VPS的话,价格方面相对比较占优势,一般低至100元一下,高至八九百左右;
第三、 功能不同:无论是承受访问量还是性能稳定方面,独立服务器都要比VPS有保证的多,另外就是独立服务器可以重装其他的操作系统,VPS只能重装原系统;
Squid是什么?怎么配置Squid?
Squid是什么?怎么配置Squid?
Squid是一种用来缓冲Internet数据的软件。它是这样实现其功能的,接受来自人
们需要下载的目标(object)的请求并适当地处理这些请求。也就是说,如果一个人想
下载一web页面,他请求Squid为他取得这个页面。Squid随之连接到远程服务器(比如
http://www.hpidc.net)并向这个页面发出请求。然后,Squid显式地聚集数据
到客户端机器,而且同时复制一份。当下一次有人需要同一页面时,Squid可以简单地
从磁盘中读到它,那样数据迅即就会传输到客户机上。当前的Squid可以处理HTTP,FT
P,GOPHER,SSL和WAIS等协议。但它不能处理如POP,NNTP,RealAudio以及其它类型的东西。
a.squid服务器上的配置
准备环境:软件包:squid(任意版本)
双网卡:eth0:192.168.1.1 eth1:10.106.34.12
如图:
vim /etc/squid/squid.conf
http_port 192.168.1.12:3128 (可写多个)
cache_mem 64MB
maximum_object_size 4096KB
reply_body_max_size 1024000 allow all
access_log /var/log/squid/access.log
visible_hostname proxy.test.xom
cache_mgr webmaster@test.com
http_access allow all
b.一切配置以后:
squid –z 初始化缓存
squid –k parse 检查语法
service squid start 启动squid
chkconfig squid on 加入开机启动
netstat –nltp 查看3128端口是否打开
c.客服端的配置:
ip : 192.168.1.12 gw:192.168.1.1
然后打开浏览器à工具à选项à连接à局域网设置à代理服务器
地址:192.168.1.1 端口:3128
一切搞定之后在浏览器输入http://www.google.cn即可访问,上网了easy吧!
透明代理缓冲服务器的配置:
a. aquid服务器上的配置与标准的代理缓冲服务器几乎一样
差别就是:http_port 192.168.1.12:3128 transparent
b.添加iptables规则:
iptables -t nat -I PREROUTING -s 192.168.1.0/24 -p tcp -dport 80 -j REDIRECT –to-ports 3128
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -p tcp –dport 53 -j SNAT -to-source 10.106.34.12
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -p udp –dport 53 -j SNAT -to-source 10.106.34.12
squid –k parse
service squid reload
c.客服端不需要在浏览器中指定代理服务器的地址,端口
但需设置上网的DNS
好了经过上三个步骤你就可以上网了
反向代理缓冲服务器配置
注意:反向代理和透明代理不能同时使用
步骤:
a. Squid服务器的设置,修改/etc/squid/squid.conf
同样反向代理aquid服务器上的配置与标准的代理缓冲服务器几乎一样
不同之处:http_port 10.106.34.12:80 vhost
Cache_peer 192.168.1.12 parent 80 0 originserver weight=5 max-conn=30
上一行的解释:定义web服务器 web服务器地址 服务器类型 http端口 icp端口 [可选项]
squid –k parse
service squid reload
b. 客服端的设置(注意:这时的客服端就是web服务器)
开启web服务
好了通过以上配置外网即可访问你的web服务器了